

This puzzle contains a large 8-bit grayscale image showing a picture of James Joyce. Here is a blown-up segment of an upper-left portion of the image:
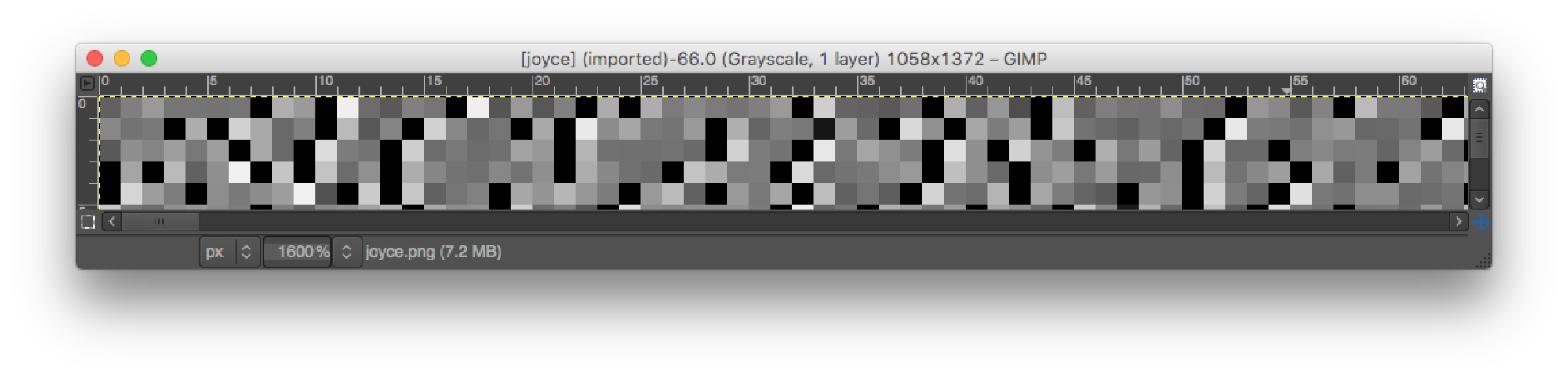
A close examination of the image reveals that it contains a large number of pure black pixels (gray level 0). Thresholding the image to show only the black pixels reveals this:
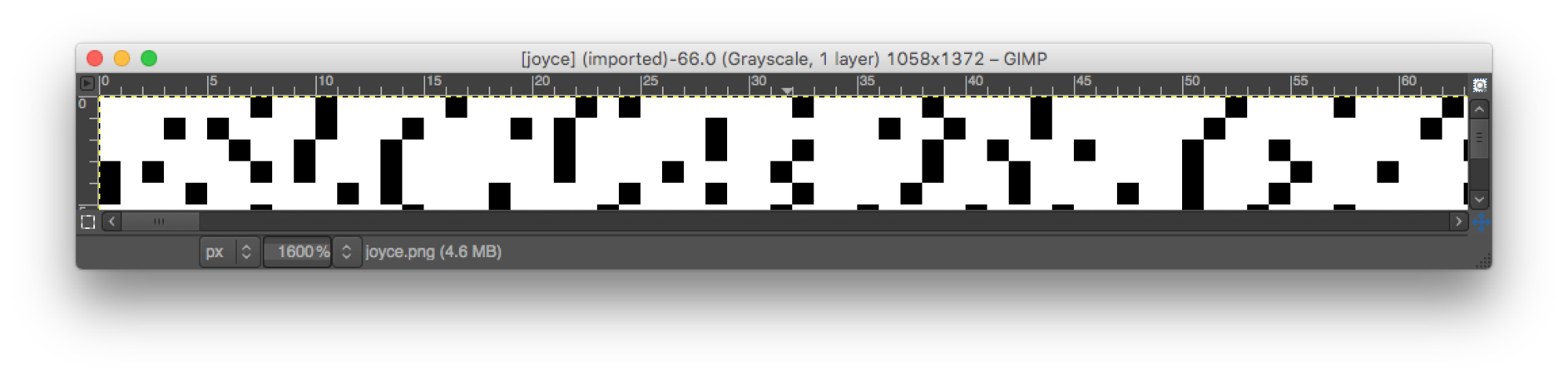
Note that black pixels are never adjacent horizontally (except for a run at the end of the image to fill out the rectangle). This fact, along with the title of the puzzle and the length distribution of horizontal runs of non-black pixels (which resembles an acrostic grid), is a clue telling solvers that the image is actually a representation of the entire text of Ulysses, with each letter in the novel corresponding to a pixel in the image. The letters/pixels are laid out in standard row-major order in the image, with all runs of non-letters compressed to a single black pixel. We can see the beginning of the book, with its title and famous first line:
ULYSSES BY JAMES JOYCE I STATELY PLUMP BUCK MULLIGAN CAME FROM
in the first row of the image by the lengths of the runs of non-black pixels.
Each of the 256 gray levels in the image maps to a particular letter of the alphabet, though there are multiple gray levels that map to the same letter. Level 0 (pure black) represents sequences of non-letters, and some gray levels are not used at all. Our reference text is Project Gutenberg’s UTF-8 edition of the novel, starting with “Ulysses by James Joyce” (so the Gutenberg preamble and licensing are stripped off). We make all letters uppercase, strip off accents (É becomes E), and expand ligature characters (Æ becomes AE). (Solvers don’t need to use this exact version of Ulysses to solve the puzzle, but it will make analysis somewhat easier.) Solvers may also need to do some manual replacement of oddball characters in the text to get it to match up exactly with the letter sequence represented by the image, but it is reasonable to see where this is needed once they have discovered much of the mapping.
Once they realize that this is an encoding of the entire text of the novel, solvers can attack this as a homophonic substitution cipher, armed with the knowledge that the plaintext is the text of Ulysses. Working out the key to this cipher yields a sequence of 256 values, with each gray level either mapping to a letter or unused (indicating a space). Level 0 maps to black (▮); levels 1–26 map to A–Z. There is another copy of the alphabet (A–Z) at the top of the range (levels 230–255, although level 255 has zero pixels assigned). In the middle of the range solvers find a long message. These are what the 256 gray levels map to:
▮ABCDEFGHIJKLMNOPQRSTUVWXYZ CONGRATULATIONS ON YOUR AMAZING STEGANOGRAPHY SKILLS TO COMPLETE PUZZLE FIND ALL PIXELS FOR THE LETTER THAT BEGINS THE CITY WHERE THE AUTHOR IS BURIED AND FORM A NEW IMAGE IN PORTRAIT ORIENTATION ABCDEFGHIJKLMNOPQRSTUVWXY
James Joyce is buried in Zurich, so we want to find all the pixels corresponding to the letter Z in the book/image. There are exactly 1073 Zs in the text (removing the preamble and dateline / Gutenberg boilerplate—the non-black image pixels tell solvers what to include); 1073 factors uniquely into 29 × 37. So a portrait-orientation image with 1073 pixels would be 29 pixels wide and 37 pixels tall. Putting just the 1073 Z pixels into such an image (packing them in row-major order) yields this image:

So the answer to this puzzle is the last word in Ulysses, which is YES.
The image of Joyce used is Berenice Abbott’s 1928 portrait in MoMA.
The following Python 3 code can be used to solve the puzzle. This implementation is based on matching the pixels of the image directly against the Project Gutenberg text file.
import re
import urllib.request as ur
from PIL import Image
import unidecode
# URL of UTF-8 encoded plain text of Ulysses at Gutenberg site
ulyssesurl = 'http://www.gutenberg.org/files/4300/4300-0.txt'
# Characters that identify start of book in image
startbook = 'ULYSSES BY JAMES JOYCE I'
# Location of saved image file from puzzle
inimagefile = 'joyce.png'
outimagefile = 'output.png'
# Read in text of Ulysses as UTF-8 encoded Unicode
with ur.urlopen(ulyssesurl) as f:
utext = f.read().decode('utf8')
# Convert to uppercase
utext = utext.upper()
# Map all runs of non-letters to a single space character
utext = re.sub('[_0-9]', ' ', utext)
utext = re.sub('\W+', ' ', utext)
# Strip off accents and expand ligatures (É becomes E; Æ becomes AE) so that all
# letters are simple A-Z characters. This can be done "by hand" using global
# substitution if needed, but this function is handy
utext = unidecode.unidecode(utext)
# Read image of Joyce
with Image.open(inimagefile) as f:
pixels = f.getdata()
# Keep track of what letter each gray level represents.
# Space means unknown or not used.
level = 256 * [' ']
# Look through image and book characters assigning level values to letters in
# matching positions in the book. Also store the levels for all Z pixels
zpixels = []
bookpos = utext.find(startbook)
for p in pixels:
if p != 0:
c = utext[bookpos]
assert(level[p] == c or level[p] == ' ')
level[p] = c
if utext[bookpos] == 'Z':
zpixels.append(p)
bookpos += 1
# Show letters associated with levels for instructions
print(''.join(level))
# Create a new image using the Z pixel levels
outimg = Image.new('L', (29, 37))
outimg.putdata(zpixels)
outimg.save(outimagefile)